
인공지능 시대를 살아가며 한 번쯤은 들어보았을 법한 단어가 바로 거대 언어 모델입니다. 우리가 일상에서 편리하게 사용하는 대화형 인공지능이 어떤 원리로 작동하는지, 그리고 그 이면에는 어떤 정교한 수학적 장치가 숨어 있는지 궁금하셨을 텐데요. 오늘은 인공지능이 마치 사람처럼 대화할 수 있게 만드는 핵심 기술인 언어 모델의 세계를 쉽고 자세하게 풀어보려 합니다.
|
구분
|
주요 내용
|
|
핵심 개념
|
다음에 올 단어를 확률적으로 예측하는 수학적 함수
|
|
학습 데이터
|
인터넷상의 방대한 텍스트 (GPT-3 기준 독서 시 2,600년 분량)
|
|
작동 원리
|
수천억 개의 파라미터를 역전파 알고리즘으로 조정하여 최적화
|
|
핵심 기술
|
트랜스포머 구조, 어텐션 메커니즘, 병렬 처리 기술
|
|
추가 학습
|
인간의 피드백을 반영한 강화 학습(RLHF)을 통한 정교화
|
문장 완성의 마법 다음에 올 단어를 예측하는 기술
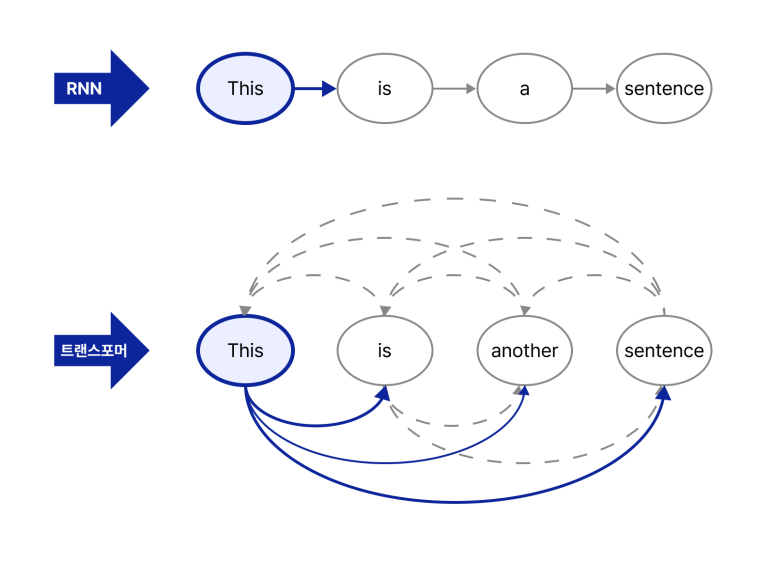
인공지능과 대화를 나누는 과정은 마치 찢어진 대본의 다음 칸을 채워 나가는 과정과 비슷합니다. 우리가 질문을 던지면 인공지능은 그 질문 뒤에 이어질 가장 적절한 단어를 찾아냅니다. 단순히 단어 하나를 골라내는 것이 아니라, 수많은 후보 단어 중 다음에 올 확률이 가장 높은 단어들을 계산해내는 정교한 수학적 함수 역할을 수행하는 것입니다.
이때 재미있는 점은 무조건 확률이 가장 높은 단어만 선택하지 않는다는 것입니다. 가끔은 확률이 조금 낮은 단어를 무작위로 섞어 선택함으로써, 답변이 너무 기계적이지 않고 사람이 말하는 것처럼 자연스러운 느낌을 주게 됩니다. 원래 언어 모델 자체는 입력에 따른 결과가 정해진 결정론적인 구조를 가지고 있지만, 이러한 무작위성을 부여함으로써 매번 조금씩 다른 생생한 답변을 생성할 수 있게 됩니다.
언어 모델의 정의와 작동 원리
|
항목
|
상세 설명
|
|
모델 정의
|
텍스트 입력 시 다음 단어의 확률 분포를 구하는 함수
|
|
결정론적 특성
|
동일 입력 시 결과가 정해져 있으나 무작위성 부여로 변수 창출
|
|
답변 생성 방식
|
단어 하나를 예측하고 이를 다시 입력에 포함해 반복 수행
|
방대한 데이터와 수천억 개의 다이얼 파라미터의 힘
이러한 언어 모델이 똑똑해지기 위해서는 엄청난 양의 독서가 필요합니다. 예를 들어 초창기 모델 중 하나인 GPT-3가 학습한 텍스트의 양은 사람이 하루 24시간 내내 쉬지 않고 읽어도 무려 2,600년 이상이 걸리는 방대한 수준입니다. 최근의 모델들은 이보다 훨씬 더 많은 데이터를 섭취하며 지식을 쌓고 있습니다.
모델 내부에는 파라미터라고 불리는 수천억 개의 미세한 다이얼들이 존재합니다. 이 다이얼들을 어떻게 맞추느냐에 따라 인공지능의 예측 결과가 달라집니다. 처음에는 이 값들이 무작위로 설정되어 있어 엉뚱한 소리를 하지만, 수많은 문장을 학습하며 실제 정답 단어와 모델의 예측 사이의 오차를 줄여나가는 과정을 거칩니다. 이를 위해 역전파 알고리즘을 사용하며, 이 과정을 무수히 반복하면 모델은 한 번도 본 적 없는 새로운 문장에 대해서도 논리적인 답변을 내놓을 수 있는 능력을 갖추게 됩니다.
학습 규모 및 최적화 과정
|
항목
|
내용 요약
|
|
학습 데이터 규모
|
수천 년 분량의 텍스트 데이터를 기반으로 지식 습득
|
|
파라미터(매개변수)
|
모델의 성능을 결정하는 수천억 개의 가중치 값
|
|
역전파 알고리즘
|
예측값과 실제값의 차이를 계산해 파라미터를 미세 조정하는 기술
|
|
연산량 규모
|
1초에 10억 번 연산 시 약 1억 년 이상 소요되는 엄청난 작업량
|
혁신의 시작 트랜스포머와 어텐션 메커니즘
인공지능 기술의 비약적인 발전은 2017년 구글 연구팀이 발표한 트랜스포머라는 구조 덕분에 가능했습니다. 이전까지는 문장의 단어를 앞에서부터 하나씩 순서대로 처리해야 했기에 속도가 느리고 긴 문맥을 파악하기 어려웠습니다. 하지만 트랜스포머는 문장 전체를 한꺼번에 병렬로 처리할 수 있는 혁신적인 방식을 도입했습니다.
여기서 가장 핵심적인 역할을 하는 것이 바로 어텐션 메커니즘입니다. 단어들은 숫자로 이루어진 벡터 형태로 변환되어 입력되는데, 어텐션은 이 벡터들이 서로 정보를 주고받으며 주변 단어와의 관계를 파악하게 돕습니다. 예를 들어 눈이라는 단어가 있을 때, 주변에 내린다라는 단어가 있으면 이를 기상 현상으로 이해하고, 예쁘다라는 단어가 있으면 사람의 신체 부위로 이해하도록 단어의 의미를 문맥에 맞게 실시간으로 조정해 줍니다. 이러한 과정을 여러 층에 걸쳐 반복하면서 인공지능은 문장 속에 숨겨진 깊은 맥락을 완벽하게 파악하게 됩니다.

핵심 기술 구조 분석
|
기술 명칭
|
주요 기능 및 역할
|
|
트랜스포머
|
전체 문장을 동시에 처리하는 병렬 연산 구조의 핵심
|
|
단어 임베딩
|
언어를 인공지능이 이해할 수 있는 숫자 벡터로 인코딩
|
|
어텐션
|
문맥에 따라 단어의 의미를 결정하고 관계성을 파악하는 연산
|
|
피드포워드
|
모델이 복잡한 언어 패턴을 기억하고 저장할 수 있게 돕는 층
|
인간의 손길로 완성되는 정교한 답변 RLHF

단순히 다음 단어를 잘 예측한다고 해서 항상 훌륭한 비서가 되는 것은 아닙니다. 때로는 논리적으로는 맞지만 사람이 듣기에 부적절하거나 무례한 답변을 내놓을 수도 있기 때문입니다. 이를 해결하기 위해 사전 훈련이 끝난 모델에 인간의 피드백을 반영하는 강화 학습 과정을 추가합니다. 이를 RLHF(인간 피드백 기반 강화 학습)라고 부릅니다.
사람이 직접 모델의 여러 답변 중 더 나은 것을 골라주거나 잘못된 부분을 수정해주면, 모델은 사용자가 더 선호하고 도움이 되는 방향으로 자신의 예측 방식을 미세하게 조정합니다. 이 과정을 통해 우리는 더욱 친절하고 유용한 인공지능과 대화할 수 있게 되는 것입니다. 비록 수천억 개의 파라미터가 정확히 왜 그런 답변을 내놓았는지 수식으로 완벽히 설명하기는 여전히 어렵지만, 그 결과물은 놀라울 정도로 자연스럽고 우리 삶에 큰 도움을 주고 있습니다.
최종 정교화 과정
|
단계
|
특징 및 목적
|
|
사전 훈련
|
방대한 데이터로부터 일반적인 언어 지식을 습득하는 단계
|
|
RLHF
|
사람의 선호도를 학습하여 답변의 품질과 유용성을 높이는 과정
|
|
GPU 활용
|
엄청난 병렬 연산을 처리하기 위해 필수적인 하드웨어 장치
|
|
결과물 특성
|
설명은 어렵지만 매우 유용하고 자연스러운 문장 생성 능력 보유
|
'인공지능' 카테고리의 다른 글
| 집에서 즐기는 나만의 고품질 음악 스튜디오 에이스텝 1.5 가이드 (0) | 2026.02.09 |
|---|---|
| 생성형 AI의 재무적 골짜기: 60조 손실을 넘기 위한 승부수 (0) | 2026.02.08 |
| 인공지능의 새로운 지평, 앤트로픽 클로드 오퍼스 4.6의 등장과 산업의 변화 (0) | 2026.02.08 |
| Qwen-TTS를 활용한 혁신적인 AI 음성 생성 가이드 (0) | 2026.02.08 |
| 차세대 AI 에이전트 통합 플랫폼 젠스파크 활용 가이드와 생산성 혁명 (0) | 2026.02.07 |



