|
구분
|
주요 내용
|
비고
|
|
핵심 기술
|
Qwen-TTS (Text-to-Speech)
|
오픈 소스 기반 고성능 음성 AI
|
|
주요 기능
|
보이스 클론, 커스텀 보이스, 보이스 디자인
|
다국어 지원 및 미세 조정 가능
|
|
장점
|
무료 이용 가능, 빠른 생성 속도, 높은 재현율
|
로컬 PC 환경에서 구동 가능
|
|
준비물
|
ComfyUI 설치 환경, 권장 사양의 GPU(또는 CPU)
|
초보자도 워크플로우로 접근 가능
|
누구나 성우가 될 수 있는 AI 음성 기술의 시작
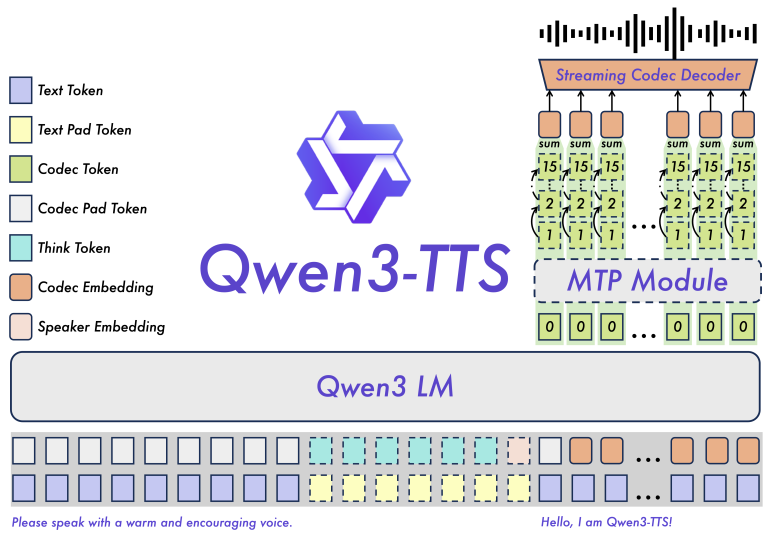
인공지능 기술이 발전하면서 이제는 단순히 글자를 읽어주는 수준을 넘어, 특정 인물의 목소리 톤과 감정까지 그대로 재현하는 단계에 이르렀습니다. 그 중심에 있는 기술 중 하나가 바로 Qwen-TTS입니다. 이 기술은 수 초 분량의 짧은 녹음 파일만 있으면 그 목소리의 특징을 잡아내어 새로운 문장을 말하게 할 수 있는 보이스 클론 기능을 제공합니다. 뿐만 아니라, 애니메이션 속 주인공 같은 귀여운 목소리나 신뢰감 있는 아나운서의 목소리도 명령어 한 줄로 뚝딱 만들어낼 수 있죠.
가장 놀라운 점은 이 모든 과정이 사용자의 개인 컴퓨터에서 이루어질 수 있다는 것입니다. 클라우드 서비스를 이용하며 매번 비용을 지불할 필요 없이, 적절한 환경만 갖춰진다면 무제한으로 고퀄리티 음성을 생성할 수 있습니다. 특히 ComfyUI라는 도구를 활용하면 복잡한 코딩 없이도 노드를 연결하는 방식으로 시각적으로 편리하게 작업할 수 있어 접근성이 매우 높습니다.
|
단계
|
항목
|
상세 설명
|
|
1단계
|
환경 구축
|
ComfyUI 설치 및 전용 커스텀 노드 추가
|
|
2단계
|
모델 준비
|
Qwen-TTS 관련 모델 자동 또는 수동 다운로드
|
|
3단계
|
워크플로우 설정
|
보이스 클론 또는 디자인 노드 배치
|
|
4단계
|
음성 생성
|
텍스트 입력 및 파라미터 조절 후 실행
|
ComfyUI를 활용한 손쉬운 설치와 설정 방법
Qwen-TTS를 가장 효율적으로 사용하는 방법은 ComfyUI의 커스텀 노드를 이용하는 것입니다. ComfyUI 매니저를 통해 Qwen-TTS를 검색하면 관련된 노드들을 쉽게 찾아 설치할 수 있습니다. 만약 검색 결과에 나오지 않는다면, ComfyUI를 최신 버전으로 업데이트(Upgrade All)하는 것이 해결책이 될 수 있습니다. 설치가 완료되고 재시작하면 준비는 끝납니다.
보통 AI 모델을 사용할 때는 대용량의 모델 파일을 직접 찾아서 특정 폴더에 넣어야 하는 번거로움이 있지만, 이 커스텀 노드는 실행 시 필요한 모델을 자동으로 감지하여 다운로드해 주는 편의성을 제공합니다. 만약 오류가 발생한다면 지정된 경로에 수동으로 모델을 배치하면 되지만, 대부분의 경우 자동 설치만으로도 충분히 작동합니다. 모델 사이즈는 보통 0.6B와 1.7B 두 가지 옵션이 있는데, 품질을 중시한다면 1.7B를, 속도를 중시한다면 0.6B를 선택하는 것이 좋습니다.
|
기능 분류
|
주요 특징
|
권장 활용처
|
|
보이스 클론
|
특정 음성 샘플을 기반으로 복제
|
나만의 목소리, 특정 인물 재현
|
|
커스텀 보이스
|
프리셋 음성을 선택하여 텍스트 낭독
|
일반적인 나레이션, 안내 방송
|
|
보이스 디자인
|
묘사를 통해 새로운 목소리 생성
|
애니메이션 캐릭터, 게임 캐릭터
|
보이스 클론과 디자인으로 만드는 나만의 콘텐츠

보이스 클론 기능을 사용하려면 복제하고 싶은 대상의 목소리가 담긴 약 3~10초 정도의 짧은 오디오 파일이 필요합니다. 이 파일을 노드에 입력하고 원하는 대사를 텍스트로 치면, 인공지능이 그 목소리의 특징을 학습하여 자연스럽게 읽어줍니다. 한국어는 물론 영어 등 다국어를 지원하며, 언어 설정을 'Auto'로 두면 시스템이 알아서 판단하여 처리해 줍니다.
보이스 디자인은 좀 더 창의적인 작업에 적합합니다. 예를 들어 "밝고 씩씩한 목소리의 여자 성우"와 같은 프롬프트를 입력하면, 인공지능이 그 묘사에 맞는 새로운 목소리를 생성해 냅니다. 같은 프롬프트를 넣더라도 생성할 때마다 조금씩 차이가 날 수 있는데, 마음에 드는 목소리가 나왔을 때는 해당 결과물의 시드(Seed) 값을 고정하여 일관성 있게 목소리를 유지할 수 있습니다. 이렇게 만든 음성은 나중에 영상 제작 도구와 결합하여 자막에 딱 맞는 생생한 목소리를 입히는 데 활용됩니다.
성능 최적화와 실제 활용 시 주의사항
음성 생성 속도는 사용자의 하드웨어 사양에 따라 다르지만, 일반적으로 생성되는 음성 길이와 비슷하거나 그 두 배 정도의 시간 내에 완료될 만큼 매우 빠릅니다. 고성능 GPU가 있다면 더욱 쾌적하겠지만, CPU만으로도 구동이 가능하다는 점이 이 기술의 큰 장점입니다. 최근에는 영상 생성 AI와 결합하여 입 모양까지 맞춰주는 '토킹 아바타' 기술로 확장되기도 하여 활용도가 무궁무진합니다.
다만, 너무나도 정교하게 목소리를 복제할 수 있기 때문에 윤리적인 측면에서의 주의가 반드시 필요합니다. 타인의 목소리를 허락 없이 복제하여 악용하는 것은 절대 금물이며, 개인적인 학습이나 창작 활동의 범주 내에서 올바르게 사용하는 태도가 중요합니다. 기술의 발전이 우리에게 큰 편리함을 주는 만큼, 그에 따르는 책임감도 잊지 말아야겠습니다.
이라거나 심층 분석과 같은 거창한 표현 없이도, Qwen-TTS는 이미 우리 곁에서 실질적인 창작 도구로서의 역할을 훌륭히 수행하고 있습니다. 초보자분들도 차근차근 설정을 따라 하신다면, 어느덧 나만의 AI 성우를 보유하게 된 놀라운 경험을 하시게 될 것입니다.
'인공지능' 카테고리의 다른 글
| 생성형 AI의 재무적 골짜기: 60조 손실을 넘기 위한 승부수 (0) | 2026.02.08 |
|---|---|
| 거대 언어 모델의 원리 탐구 (0) | 2026.02.08 |
| 인공지능의 새로운 지평, 앤트로픽 클로드 오퍼스 4.6의 등장과 산업의 변화 (0) | 2026.02.08 |
| 차세대 AI 에이전트 통합 플랫폼 젠스파크 활용 가이드와 생산성 혁명 (0) | 2026.02.07 |
| 삼성전자의 독자 GPU 아키텍처 개발 추진 현황 및 기술적 과제 (1) | 2026.02.07 |



